
The SARS-CoV-2 pandemic presents a serious challenge to healthcare, economies and societies across the globe, one that has demanded an unprecedented scientific response. Projects across multiple disciplines are now re-directing their usual analytical efforts to meet this challenge head-on, and GENCODE are no exception. Our project produces human gene annotation, and we’re contributing to this scientific effort by re-examining human genes that may be relevant to viral infection and COVID-19 disease. We hope this work will support further research along these lines. For example, updated gene annotation could benefit studies to find disease-linked variants in patients with severe COVID-19 symptoms, including work by Genomics England and others.
In general, we find that the annotation for a given gene can be updated along several lines. Firstly, we can typically add more transcript models, using transcriptomics data that was not available when the gene was annotated originally (e.g. from ‘long-read’ sequencing libraries, including those produced by our partners at the Centre for Genomic Regulation in Barcelona). Similarly, we can also use new data to improve the structures of existing models, especially by extending ‘incomplete’ models to their full lengths. We also re-appraise the ‘functional’ annotation of the gene, considering in particular whether our inferences into the protein isoforms translated from the various alternatively spliced transcripts are appropriate. The accuracy of coding region predictions typically can be improved by incorporating more in-depth ‘comparative annotation’, whereby we compare human genome regions against other species, looking for the tell-tale signs of sequence evolution at the amino acid level. Modern proteomics datasets can also help, where available.
One gene of confirmed importance for SARS-CoV-2 infection – and thus an obvious place to start – is TMPRSS2, which encodes a transmembrane protein used by the viral particle to facilitate entry into the host cell. We have now updated our gene annotation for TMPRSS2, adding ten transcript models and extending two existing models. These improvements can be seen here:

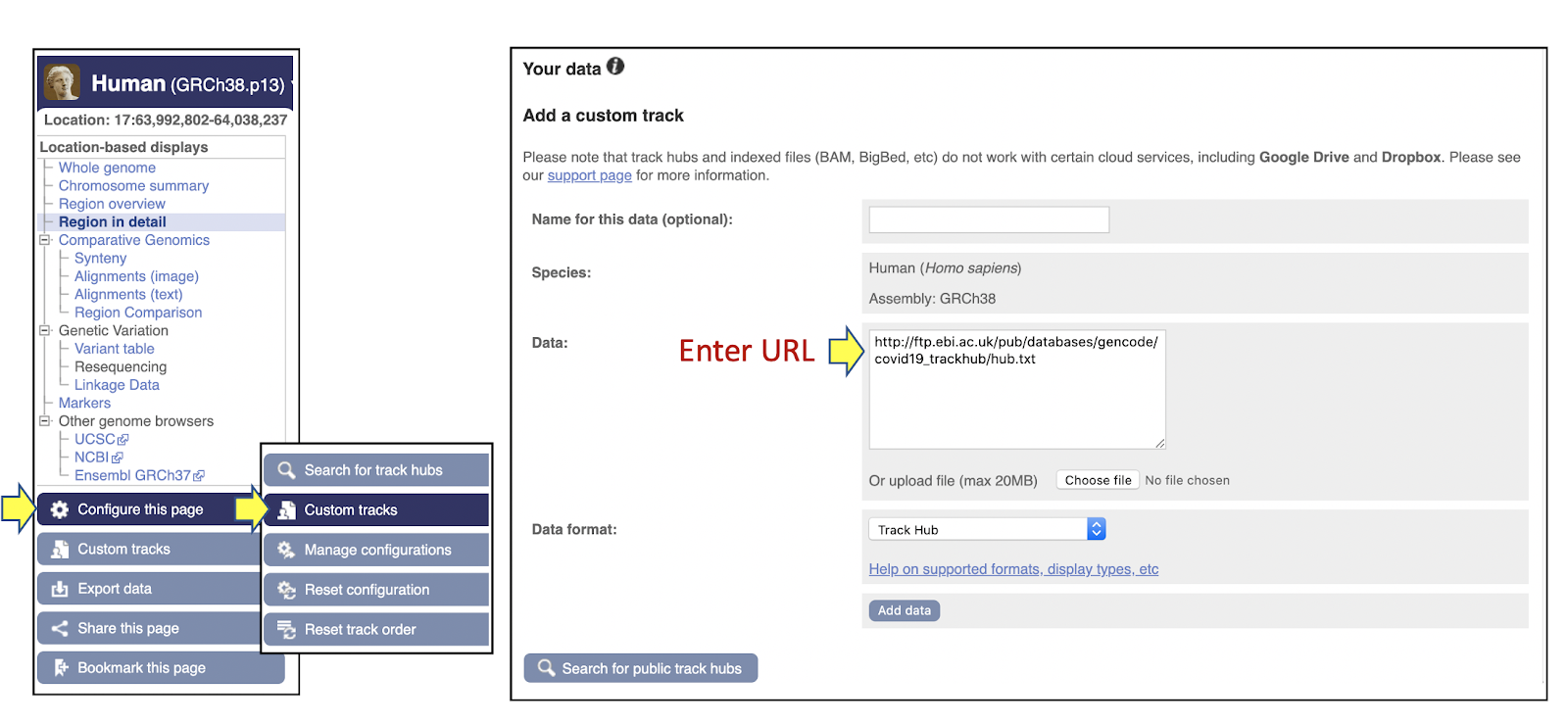
You’re looking at the modified TMPRSS2 annotation in the Ensembl genome browser, specifically within our new ‘COVID-19 genes’ track hub. The pre-existing annotation in Ensembl release 100 is shown above for comparison. Changes to gene annotation take months to appear in our official GENCODE / Ensembl releases; in contrast the track hub allows us to release new and modified annotations publicly within 24 hours. It contains all transcripts now annotated within the TMPRSS2 gene; models that are unchanged with respect to release 100 are coloured blue, whereas new models or pre-existing models that have been modified are shown in orange. Note that all new models have an Ensembl transcript ID that will be used in the future official release. As shown below, the track hub can be uploaded by inserting this link as a ‘custom track’ in the Ensembl browser, or by searching the Track Hub Registry for ‘COVID-19’. Alternatively, the corresponding BED and gtf files can be found here.
We are now in the process of re-annotating additional genes linked to COVID-19 disease. It is important to note that – in contrast to TMPRSS2 – the involvement of many of these genes in infection or disease falls somewhere on the scale between ‘inferred’ and ‘speculated’. To be clear, we are not looking to provide a comprehensive list of human genes that are relevant to viral infection and disease. Instead, we are working to improve the annotation of any gene that seems as if it could be relevant. Thus, we anticipate that certain genes on our list may ultimately turn out to be of no direct interest to researchers working on COVID-19. Similarly, even for established genes like TMPRSS2, we emphasise that our re-annotation process is judging the expression and function of the various transcripts within the locus in a general scientific context and according to our usual annotation criteria. There are clear limits to what can be established based on gene annotation alone, and at this point we make no claims about the potential medical importance of any given transcript model.
So far, we have re-annotated 145 genes, adding 1,874 new transcript models and modifying 454 existing models. The GENCODE website provides the gene list, and also details how it was derived. We are prepared to work on this for some weeks, and potentially for months if required. Indeed, we expect that genes of interest will continue to appear in the literature, including – potentially – candidate loci identified by GWAS studies examining variation in the severity of COVID-19 disease. Also, if you think there are any additional genes that should already be on our list – or you would like any aspects of the annotation for your favourite gene explained – then please contact us.
Finally, we are of course not working in isolation on this. Other annotation groups are also working hard to make their own contributions, and we are now pooling our efforts with those of the UniProt group. Most obviously we are now working on the same gene list, and you may wish to investigate their pre-release data site to find further information on this topic.